Introduction
과연 로봇이 주변 환경을 인지하기 위해 SLAM의 결과물로 explicit한 표현을 하는 것이 옳은 방향일까? 이 글에서는 Aswin과 마지막으로 코웍한 DreamWaQ++에 대해서 설명한다. 나는 SLAM맨이다보니, control/RL 쪽에서 자주 나오는 MDP, POMDP, privileged learning, belief와 같은 단어들과 그리 친숙하지는 않아서 바짝 볼떄는 이해하고 있다가 시간이 지나면 자꾸 개념을 점점 잊게 되는 것을 느꼈다. 그래서 이 글은 DreamWaQ++를 홍보하려고 쓰는 글이라기보다, 내가 SLAM/perception 연구자 입장에서 이 논문을 다시 이해하기 위해 남기는 공부 노트에 가깝다.
내가 이해한 결론부터 말하면 이렇다.
DreamWaQ++는 “정확한 map을 만든 뒤 control하자”가 아니라, “로봇이 지금 action을 고르기 위해 필요한 hidden context를 multi-modal observation history에서 추정하자”에 가까운 논문이다.
이 관점으로 보면 POMDP라는 말도 조금 덜 무섭다. POMDP는 결국 “로봇이 세상의 진짜 state를 다 보고 있지는 않다”는 사실을 정직하게 인정하는 모델이다.
MDP부터 다시 보기
먼저 MDP부터 보자. MDP는 Markov Decision Process의 약자이다. 이름은 거창하지만, robotics 관점에서는 다음처럼 생각하면 된다.
어떤 시점 \(t\)에서 system의 state가 \(s_t\)이고, robot이 action \(a_t\)를 하면, 다음 state \(s_{t+1}\)와 reward \(r_t\)가 정해진 확률분포에서 나온다.
중요한 것은 Markov property이다.
현재 state s_t가 충분히 완전하다면,
미래를 예측하는 데 과거 history가 더 필요하지 않다.
즉 \(s_t\) 안에 필요한 정보가 다 들어있다면, 이전 observation이나 action을 길게 들고 있을 필요가 없다.
예를 들어 아주 이상적인 quadruped simulation을 생각해보자. state에 다음 정보가 모두 들어있다고 하자.
- base pose와 velocity
- joint position과 joint velocity
- foot contact 상태
- terrain geometry
- friction
- motor strength
- payload
- external disturbance
이 정도가 완벽하게 들어있으면, 현재 state와 action만 보고 다음 state를 예측할 수 있다. 이것이 MDP에 가까운 세상이다.
하지만 real robot에서는 이런 일이 거의 일어나지 않는다.
그러면 왜 POMDP인가
POMDP는 Partially Observable Markov Decision Process이다. 말 그대로 state를 partially observable하게 본다는 뜻이다.
여기서 헷갈리기 쉬운 점은 state와 observation을 구분하는 것이다.
state: 세상이 실제로 가지고 있는 완전한 정보
observation: robot이 sensor로 실제로 받은 정보
Legged robot에서 진짜 state는 생각보다 크다. 로봇 내부 상태만 있는 것이 아니다. 바닥의 마찰, 계단의 edge, 발밑의 미세한 높이, 발이 곧 닿을 곳의 geometry, actuator delay, sensor delay, extrinsic calibration error, 외부 충격까지 모두 미래 motion에 영향을 준다.
그런데 robot이 실제로 받는 observation은 제한적이다.
- IMU는 base orientation과 angular velocity 일부를 준다.
- joint encoder는 joint 상태를 준다.
- depth camera나 LiDAR는 시야 안의 geometry만 준다.
- 발밑이나 몸통 아래의 terrain은 지금 당장 안 보일 수 있다.
- exteroceptive sensor는 control loop보다 느리다.
- sensor data에는 latency, noise, dropout이 있다.
즉 robot은 진짜 state \(s_t\)를 직접 보지 못하고, observation \(o_t\)만 본다. 그래서 현재 observation 하나만으로 action을 고르면 정보가 부족하다.
이때 필요한 것이 history이다.
o_0, a_0, o_1, a_1, ..., o_t
이 history를 바탕으로 “지금 세상이 어떤 state일 가능성이 높은가”를 추정해야 한다. RL에서는 이것을 belief라고 부른다.
엄밀하게 쓰면 belief는 이런 것이다.
\[b_t = p(s_t | o_{0:t}, a_{0:t-1})\]수식은 복잡해 보이지만 의미는 단순하다.
지금까지 본 observation과 내가 했던 action들을 바탕으로, 현재 hidden state가 무엇일지에 대한 나의 추정.
이 관점에서 보면 POMDP는 SLAM과 굉장히 닮아 있다(나의 개인적인 의견). SLAM도 결국 sensor history를 이용해서 robot pose와 map이라는 hidden state를 추정한다. 다만 legged locomotion에서는 hidden state가 pose와 map만이 아니다. terrain, contact, friction, actuator condition, sensor delay까지 action에 영향을 주는 모든 것이 hidden context가 된다.
Actor-Critic부터 이해하기
DreamWaQ++를 읽다 보면 actor-critic이라는 말이 나온다. 처음에는 이것도 약간 헷갈린다. actor는 뭔가 행동하는 녀석 같고, critic은 비평가 같기는 한데, 정확히 강화학습에서 어떤 역할을 하는지 감이 잘 안 잡힐 수 있다.
내가 이해한 actor-critic의 핵심은 다음과 같다.
actor:
observation 또는 state를 보고 action을 고르는 policy
critic:
actor가 고른 action 또는 현재 state가 얼마나 좋은지 평가하는 value estimator
즉 actor는 로봇을 실제로 움직이는 쪽이다. 어떤 observation \(o_t\)가 들어오면 actor는 action \(a_t\)를 낸다.
예를 들어 locomotion policy라면 actor는 이런 일을 한다.
현재 joint 상태, IMU, terrain context를 보고
다음 target joint position을 출력한다.
반면 critic은 직접 로봇을 움직이지 않는다. critic은 현재 상태가 장기적으로 얼마나 좋은지, 혹은 지금 action이 앞으로 reward를 얼마나 만들 것 같은지 평가한다.
가장 단순하게 쓰면 다음처럼 볼 수 있다.
\[\pi_\theta(a_t | o_t)\]는 actor이다. observation \(o_t\)를 보고 action distribution을 낸다.
반면
\[V_\phi(o_t)\]는 critic이다. 현재 observation에서 앞으로 얻을 reward의 기대값을 추정한다.
여기서 중요한 점은 actor가 학습할 때 critic의 평가를 사용한다는 것이다. 예를 들어 actor가 어떤 action을 했는데 결과가 좋았다면, 그 action이 다시 나올 확률을 높이는 방향으로 policy를 업데이트한다. 반대로 결과가 나빴다면 그 action이 덜 나오게 만든다.
그런데 실제 강화학습에서는 “좋았다”와 “나빴다”를 판단하는 것이 쉽지 않다. 한 step reward만 보면 애매한 경우가 많기 때문이다.
예를 들어 로봇이 계단 앞에서 발을 높게 들었다고 하자. 그 순간에는 에너지를 많이 썼으니 reward가 낮아 보일 수도 있다. 하지만 몇 step 뒤에 넘어지지 않고 계단을 잘 올라갔다면 좋은 action이었을 수 있다.
critic은 이런 장기적인 효과를 추정해서 actor가 더 안정적으로 학습하도록 도와준다. 그래서 PPO 같은 방법에서 critic은 policy gradient의 variance를 줄이고, 학습을 더 안정적으로 만드는 역할을 한다고 이해하면 된다.
일반적인 actor-critic 구조에서는 actor와 critic이 보통 같은 종류의 정보를 본다.
actor:
observation/state -> action
critic:
observation/state -> value
예를 들어 둘 다 현재 observation \(o_t\)를 본다면 다음과 같다.
actor: pi(a_t | o_t)
critic: V(o_t)
즉 일반 actor-critic에서는 actor와 critic이 보는 입력이 같거나 거의 비슷하다.
PPO는 무엇인가
위에서 PPO라는 말을 잠깐 썼다. DreamWaQ++ 논문에서도 policy를 학습할 때 PPO를 사용한다.
PPO는 Proximal Policy Optimization의 약자이다. 이름만 보면 최적화 이론 느낌이 강한데, 내가 이해한 핵심은 다음과 같다.
PPO는 policy를 업데이트하되, 한 번에 너무 많이 바뀌지 않도록 제한하는 actor-critic 기반 강화학습 방법이다.
강화학습에서 actor는 action을 고르는 policy이다. 예를 들어 현재 policy가 어떤 observation에서 action \(a_t\)를 골랐고, 그 결과가 좋았다면 다음에는 그 action이 더 자주 나오도록 policy를 바꾸고 싶다. 반대로 결과가 나빴다면 그 action이 덜 나오게 만들고 싶다.
이런 계열을 broadly하게 policy gradient라고 보면 된다. policy parameter \(\theta\)를 reward가 커지는 방향으로 업데이트하는 것이다.
하지만 문제가 있다. policy를 너무 크게 업데이트하면 갑자기 행동이 망가질 수 있다. 특히 locomotion에서는 이 문제가 치명적이다. 조금 전까지 잘 걷던 policy가 update 한 번으로 다리를 이상하게 뻗고 바로 넘어질 수 있다.
PPO는 이 문제를 막기 위해 “새 policy가 이전 policy에서 너무 멀리 가지 않도록” 제한한다. 핵심 아이디어는 old policy와 new policy의 action probability 비율을 보는 것이다.
\[r_t(\theta) = \frac{\pi_\theta(a_t | o_t)} {\pi_{\theta_{\text{old}}}(a_t | o_t)}\]여기서 \(r_t(\theta)\)는 같은 observation에서 같은 action을 낼 확률이, 새 policy에서 얼마나 바뀌었는지를 나타낸다.
- \(r_t = 1\)이면 새 policy와 old policy가 그 action을 비슷하게 본다.
- \(r_t > 1\)이면 새 policy가 그 action을 더 선호한다.
- \(r_t < 1\)이면 새 policy가 그 action을 덜 선호한다.
PPO는 이 비율이 너무 커지거나 작아지지 않게 clipping한다. 보통 \(1-\epsilon\)과 \(1+\epsilon\) 사이 정도로 update 효과를 제한한다.
그래서 PPO의 감각은 이렇다.
좋은 action은 더 자주 나오게 만들자.
나쁜 action은 덜 나오게 만들자.
하지만 policy를 한 번에 너무 심하게 바꾸지는 말자.
여기서 critic이 다시 등장한다. 어떤 action이 좋은지 나쁜지를 판단하려면 기준이 필요하다. critic은 현재 observation의 value \(V(o_t)\)를 추정하고, 실제로 얻은 return이 그 value보다 얼마나 좋은지 계산하는 데 쓰인다. 이 차이를 보통 advantage라고 부른다.
직관적으로는 다음과 같다.
advantage > 0:
생각보다 좋았다.
이 action이 더 자주 나오게 하자.
advantage < 0:
생각보다 나빴다.
이 action이 덜 나오게 하자.
그래서 PPO는 actor와 critic이 같이 필요하다.
- actor는 action distribution을 만든다.
- critic은 value를 추정해서 advantage 계산을 도와준다.
- PPO는 advantage를 이용해 actor를 업데이트하되, update 폭을 clipping으로 제한한다.
Legged locomotion에서 PPO가 자주 쓰이는 이유도 여기에 있다. 수많은 robot을 simulation에서 병렬로 굴리면서 데이터를 모을 수 있고, policy update가 비교적 안정적이라 continuous control 문제에 잘 맞는다.
DreamWaQ++ 그림에서 보면, critic network에서 policy network 쪽으로 가는 빨간 dashed line이 policy gradient이다. 이때 PPO는 critic의 value estimate를 활용해서 actor인 policy network를 업데이트한다. 다만 앞서 말했듯이 실제 robot에 올라가는 것은 critic이 아니라 actor이다.
Asymmetric Actor-Critic은 무엇이 다른가
그러면 asymmetric actor-critic은 무엇이 다른가? 말 그대로 actor와 critic이 보는 정보가 대칭적이지 않다.
일반 actor-critic이 다음과 같다면,
actor: observation/state -> action
critic: observation/state -> value
asymmetric actor-critic은 다음과 같다.
actor:
실제 robot에서도 얻을 수 있는 partial observation만 봄
critic:
simulation에서만 알 수 있는 privileged state까지 봄
즉 actor는 deployment 조건과 맞춰야 한다. 실제 로봇에서는 ground-truth terrain property나 external force, 정확한 foot contact 상태 같은 것을 알 수 없다. 그래서 actor에게 이런 정보를 주면 안 된다. 실제 robot에 올릴 수 없기 때문이다.
반면 critic은 training 때만 쓰인다. deployment 때는 critic을 버리고 actor만 사용한다. 따라서 critic은 simulation에서 알 수 있는 더 많은 정보를 봐도 된다.
이걸 비유하면 다음과 같다.
actor:
실제 시험을 보는 학생
critic:
연습 과정에서 더 정확하게 채점해주는 선생님
학생은 시험장에서 답지를 볼 수 없다. 하지만 연습할 때 선생님은 정답지를 보고 더 정확하게 피드백을 줄 수 있다. 그렇다고 해서 실제 시험에서 cheating을 하는 것은 아니다. 시험장에는 학생만 들어가기 때문이다.
DreamWaQ++에서 asymmetric actor-critic을 쓰는 이유도 여기에 있다. legged robot은 POMDP 상황에 있다. actor는 세상의 진짜 state를 다 보지 못한다. 하지만 critic은 simulation에서 더 완전한 state를 보고 actor를 더 잘 학습시킬 수 있다.
정리하면 다음과 같다.
| 구조 | Actor 입력 | Critic 입력 | 특징 |
|---|---|---|---|
| Actor-Critic | actor와 critic이 비슷한 observation/state를 봄 | 같거나 거의 같음 | 기본 구조 |
| Asymmetric Actor-Critic | 실제 배포 가능한 partial observation만 봄 | simulation privileged state까지 봄 | POMDP, sim-to-real에서 유용 |
한 줄로 말하면 이렇다.
asymmetric actor-critic은 training 때 critic에게만 더 좋은 정보를 보여주고, 실제 deployment 때는 actor가 real-world observation만으로 동작하게 만드는 방법이다.
DreamWaQ++에서의 POMDP 활용
DreamWaQ++를 POMDP 관점에서 보면 구조가 조금 선명해진다.
먼저 전체 구조를 그림으로 보면 다음과 같다.
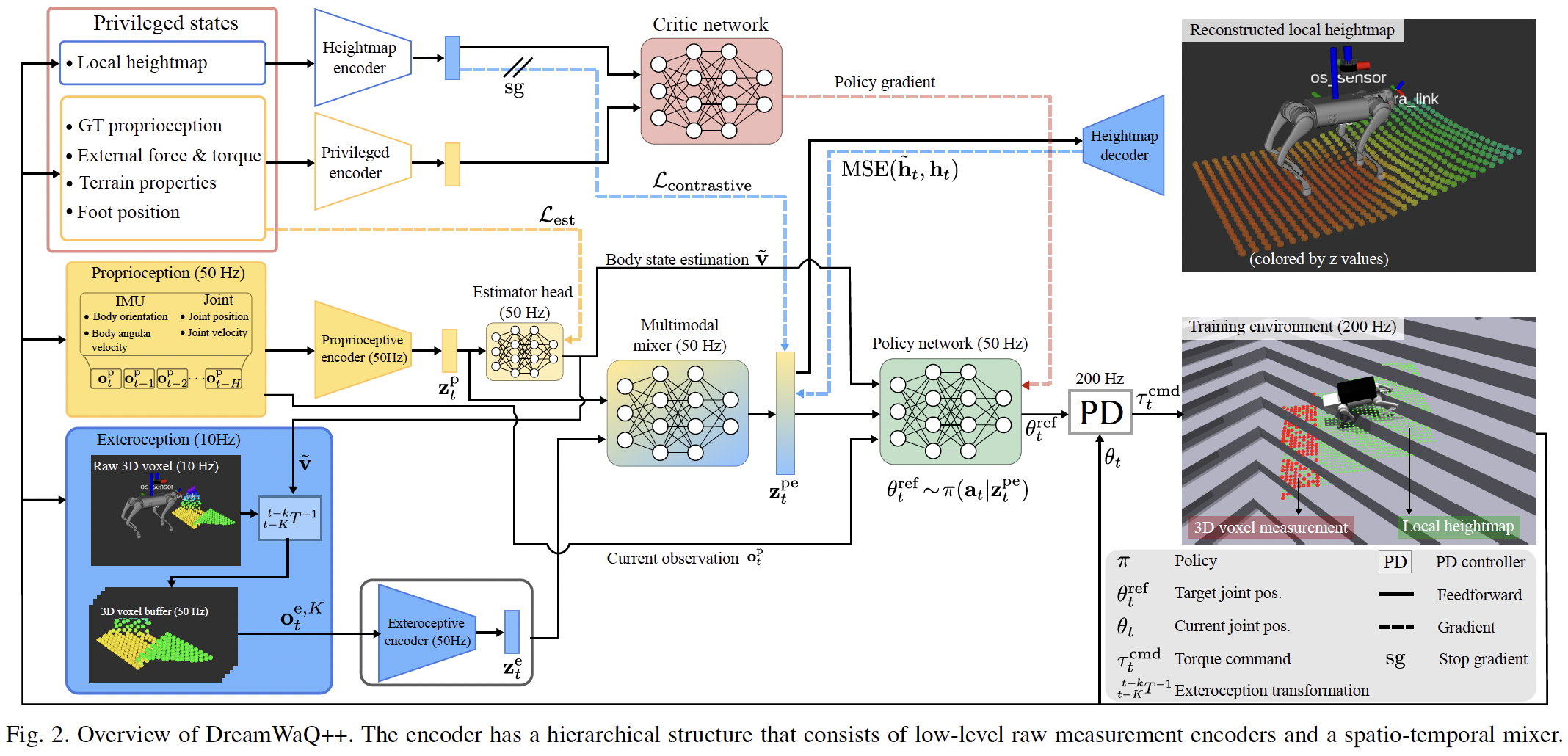
그림이 복잡해 보이지만, 크게 보면 질문은 하나이다.
실제 로봇에서 관측 가능한 sensor 정보만으로
어떻게 policy가 좋은 action을 고르게 만들 것인가?
이를 위해 DreamWaQ++는 actor와 critic을 다르게 설계한다. 논문에서 actor는 real-world와 비슷한 partial observation을 받는다. 반면 critic은 simulation에서만 접근 가능한 privileged state를 받는다. 이것을 asymmetric actor-critic이라고 부른다.
여기서 actor와 critic이 처음 보면 헷갈린다. 내 식으로 이해하면 다음과 같다.
actor:
실제로 로봇을 움직이는 policy.
observation을 보고 action을 낸다.
critic:
training 때만 쓰는 평가자.
actor가 고른 action이 장기적으로 좋은지 value를 추정한다.
즉 actor는 “무엇을 할지 결정하는 network”이고, critic은 “그 결정이 얼마나 좋은지 평가해서 actor를 학습시키는 network”이다.
강화학습에서는 actor가 action을 내고, 그 action으로 얻은 reward를 바탕으로 policy를 업데이트한다. 그런데 매번 action이 좋은지 나쁜지 즉시 알기 어렵다. 예를 들어 계단 앞에서 발을 조금 더 높게 든 action이 좋은지 나쁜지는, 당장 한 step reward만 봐서는 잘 모를 수 있다. 몇 step 뒤에 안정적으로 올라갔는지, 넘어졌는지까지 봐야 한다.
critic은 이때 현재 상태의 expected future reward, 즉 value를 추정한다. PPO 같은 actor-critic RL에서는 critic이 추정한 value를 이용해서 actor의 policy gradient를 더 안정적으로 계산한다.
중요한 점은 이것이다.
critic은 training을 도와주는 선생님이고, 실제 robot deployment 때는 actor만 사용된다.
그래서 critic이 privileged state를 보는 것은 cheating이 아니다. 시험장에서 답지를 보는 것이 아니라, 연습할 때 더 좋은 채점자를 두는 것에 가깝다.
처음에는 이 구조가 그냥 trick처럼 보일 수 있다. 하지만 POMDP 관점에서는 꽤 자연스럽다.
critic:
training 중에 더 완전한 state를 보고 value를 잘 평가한다.
actor:
deployment 때 실제로 쓸 수 있는 observation과 latent context만 보고 action을 낸다.
그림에서 이 구조는 다음처럼 보인다.
-
Privileged states 왼쪽 위 빨간 박스이다. local heightmap, ground-truth proprioception, external force/torque, terrain properties, foot position 같은 정보가 들어간다. 이 정보들은 simulation에서는 알 수 있지만 실제 로봇에서는 직접 얻기 어렵다.
-
Critic network 위쪽의 분홍색 network이다. privileged states에서 나온 feature를 받아 value를 추정한다. 그림에서 critic에서 policy 쪽으로 이어지는 빨간 dashed line이 policy gradient이다. critic이 직접 로봇을 움직이는 것이 아니라, actor를 학습시키는 방향을 알려주는 역할을 한다.
-
Policy network 오른쪽 아래 초록색 network이다. 이것이 actor이다. 현재 proprioception \(o_t^p\)와 multi-modal context \(z_t^{pe}\)를 받아 target joint position \(\theta_t^{ref}\)를 출력한다. 실제 deployment에서 로봇에 올라가는 핵심 network가 이 actor이다.
-
PD controller actor가 바로 torque를 내는 것이 아니라, target joint position을 낸다. 그 다음 200 Hz PD controller가 현재 joint position \(\theta_t\)와 target \(\theta_t^{ref}\)의 차이를 보고 torque command \(\tau_t^{cmd}\)를 만든다.
즉 그림을 한 줄로 요약하면 다음과 같다.
critic은 privileged state를 보고 training을 안정화하고,
actor는 실제 sensor로부터 만든 latent context를 보고 joint target을 낸다.
실제 robot에 올라가는 actor는 privileged information을 쓰지 않는다. actor가 쓰는 것은 proprioception, exteroception, 그리고 encoder가 만든 context latent이다.
여기서 context latent가 중요하다. 이 latent는 단순 feature vector가 아니다. 내가 보기에는 belief의 압축된 근사에 가깝다.
정확히 말하면 논문에서 latent를 Bayesian filtering의 belief라고 주장하는 것은 아니다. 하지만 역할은 비슷하다.
현재 observation 하나로 부족한 정보를
짧은 history와 multi-modal sensing에서 추정해서
policy가 action을 고를 수 있게 해준다.
이게 POMDP에서 memory가 필요한 이유이다.
Figure 2를 SLAM Researcher 관점에서 다시 보기
위 그림을 SLAM/perception 관점에서 보면 더 재미있다. 전체 그림은 크게 네 흐름으로 나눌 수 있다.
1. Proprioception 흐름
왼쪽 중간의 노란 박스가 proprioception이다. 여기에는 IMU와 joint encoder 정보가 들어간다.
- body orientation
- body angular velocity
- joint position
- joint velocity
- 짧은 observation history
이 정보는 50 Hz로 들어가고, proprioceptive encoder를 거쳐 \(z_t^p\)라는 latent가 된다. 또 estimator head는 body velocity \(\tilde{v}\)를 추정한다.
SLAM 관점에서 보면 이 부분은 visual-inertial odometry의 IMU propagation처럼, 외부 sensing이 느리거나 불완전할 때 robot의 short-term motion context를 유지하는 역할을 한다. 다만 여기서는 pose graph를 만들기 위한 것이 아니라, policy가 바로 쓸 body context를 만들기 위한 것이다.
2. Exteroception 흐름
왼쪽 아래 파란 박스가 exteroception이다. raw 3D voxel 또는 point cloud measurement가 10 Hz로 들어온다. 그런데 policy는 50 Hz로 돈다. 즉 매 policy step마다 새로운 3D measurement가 있는 것이 아니다.
그래서 DreamWaQ++는 과거 exteroceptive measurement를 현재 body frame으로 transform해서 buffer에 쌓는다. 그림의 3D voxel buffer가 이 부분이다. 이렇게 만든 \(o_t^{e,K}\)가 exteroceptive encoder로 들어가고, \(z_t^e\)라는 latent가 나온다.
이 부분은 SLAM의 local map fusion과 닮아 있다. 하지만 목표는 globally consistent map이 아니다. 목표는 “지금 policy가 쓸 수 있는 robot-centric local geometry”를 만드는 것이다.
3. Multi-modal mixer
가운데의 multi-modal mixer는 proprioceptive latent \(z_t^p\)와 exteroceptive latent \(z_t^e\)를 합쳐서 \(z_t^{pe}\)를 만든다. 여기서 \(pe\)는 proprioception + exteroception이라고 보면 된다.
이 latent가 중요한 이유는, policy가 raw point cloud나 raw joint history를 직접 다루는 것이 아니라, action을 고르는 데 필요한 형태로 압축된 context를 받기 때문이다.
내가 보기에는 이 \(z_t^{pe}\)가 DreamWaQ++에서 가장 POMDP스러운 부분이다. 현재 observation 하나로는 알 수 없는 terrain과 robot 상태를 history에서 추정한 belief-like representation이기 때문이다.
4. Auxiliary losses
그림에는 gradient line도 여러 개 있다. 처음 보면 복잡하지만, 대부분 encoder가 의미 있는 latent를 만들도록 돕는 auxiliary objective이다.
- \(L_{est}\): body state estimation loss이다. proprioceptive encoder가 body velocity를 잘 추정하도록 만든다.
- heightmap reconstruction: multi-modal latent에서 local heightmap을 복원하게 해서 지형 정보를 latent에 담도록 만든다.
- \(L_{contrastive}\): privileged heightmap feature와 actor가 보는 partial observation feature를 latent space에서 맞추려는 역할을 한다.
즉 policy reward만으로 모든 것을 배우게 두지 않고, latent가 지형과 body context를 잘 담도록 여러 학습 신호를 추가한 것이다.
Actor와 Critic을 SLAM식으로 비유하면
SLAM 쪽 사람에게 actor와 critic을 비유하자면 이렇게 볼 수 있다.
actor는 online estimator에 가깝다. 실제 sensor stream만 보고, 실시간으로 결정을 내려야 한다. 계산 시간도 제한되어 있고, input도 noisy하고 partial하다.
critic은 training-time evaluator에 가깝다. simulation에서만 볼 수 있는 더 완전한 정보를 보고, actor가 만든 행동이 좋은지 나쁜지 더 정확히 평가한다.
다만 critic은 deployment 때 사라진다. 따라서 실제 시스템 관점에서 중요한 것은 actor가 어떤 observation을 받아 어떤 action을 내는가이다.
이 점 때문에 DreamWaQ++의 설계 철학이 보인다.
training 때는 privileged information을 최대한 활용하되,
deployment 때는 real robot에서 얻을 수 있는 sensor만으로 돌아가게 만든다.
이것이 asymmetric actor-critic의 핵심이다.
Proprioception만으로는 왜 부족한가
Blind locomotion은 생각보다 강하다. joint와 IMU만으로도 로봇은 꽤 많은 지형을 버틴다. 발이 terrain에 닿으면 그 반응이 proprioception으로 들어오기 때문이다.
하지만 한계도 명확하다(그래서 1저자인 Aswin이 DreamWaQ에서 DreamWaQ++로 연구를 확장했다).
Blind policy는 기본적으로 부딪힌 뒤에야 알 수 있다. 계단이 있는지, gap이 있는지, 발을 어디에 뻗어야 하는지 미리 알기 어렵다. 그래서 robust하기는 하지만, obstacle-aware하다고 말하기는 어렵다.
SLAM/perception 연구자 입장에서는 이 지점이 중요하다. 우리가 제공해야 하는 것은 예쁜 point cloud나 globally consistent map 자체가 아닐 수 있다. control policy 입장에서는 다음 질문이 더 중요하다.
앞에 계단이 있는가?
발을 높게 들어야 하는가?
어느 쪽이 더 낮고 안전한가?
여기는 밟아도 되는가?
지금 보이는 geometry를 믿어도 되는가?
DreamWaQ++는 이 질문에 답하기 위해 exteroception을 넣는다. 하지만 여기서도 핵심은 map reconstruction이 아니다. 핵심은 policy가 쓸 수 있는 context를 만드는 것이다.
Exteroceptive Memory의 의미
Legged robot에서 exteroceptive sensing은 control보다 느리다. 예를 들어 depth나 LiDAR는 10 Hz 근처일 수 있고, policy는 50 Hz, low-level PD는 200 Hz 이상으로 돈다. 이러면 매 control step마다 새로운 point cloud가 들어오지 않는다.
게다가 sensor는 robot body에 붙어 있고, robot은 계속 흔들린다. 과거 point cloud를 그대로 쓰면 현재 body frame과 맞지 않는다.
DreamWaQ++에서는 과거 exteroceptive observation을 현재 robot frame으로 transform해서 쌓는다. 짧은 시간 동안의 point들을 현재 기준으로 정렬해서, policy가 더 dense하고 안정적인 local geometry를 볼 수 있게 한다.
이 부분은 SLAM 연구자에게 익숙한 사고방식이다. 결국 과거 sensor measurement를 현재 frame으로 가져와 fusion하는 것이다. 다만 목적이 다르다.
전통적인 SLAM에서는 보통 이런 질문을 한다.
world frame에서 robot pose와 map을 어떻게 일관되게 추정할 것인가?
DreamWaQ++의 exteroceptive memory는 조금 더 control-facing하다.
지금 policy가 action을 고르는 데 필요한 local geometry를 어떻게 안정적으로 제공할 것인가?
여기서는 global consistency보다 latency와 local usefulness가 더 중요하다. 몇 초 뒤 loop closure를 잘 맞추는 것보다, 지금 다음 발을 어디에 둘지 판단하는 것이 더 급하다.
Map이 아니라 Interface일 수 있다
SLAM을 오래 하다 보면 map을 최종 결과물처럼 생각하기 쉽다. trajectory가 정확하고, map이 선명하고, loop closure 이후 globally consistent하면 좋은 시스템이라고 느낀다.
물론 그것은 여전히 중요하다. 하지만 legged locomotion을 보면 map은 최종 결과물이 아니라 interface에 가깝다는 생각이 든다.
즉 perception module은 control module에게 다음과 같은 interface를 제공해야 한다.
- robot-centric local geometry
- terrain height and slope
- edge or gap likelihood
- traversability
- contact risk
- uncertainty or confidence
- time delay information
여기서 중요한 점은 “얼마나 정확한가”만이 아니다. control이 쓸 수 있는 형태인가가 더 중요하다.
아주 정확한 global map이 있어도 policy가 50 Hz로 쓸 수 없으면 locomotion에는 애매하다. 반대로 global consistency는 부족해도, local terrain context를 낮은 latency로 안정적으로 주면 control에는 훨씬 유용할 수 있다.
이것이 내가 DreamWaQ++를 보면서 SLAM에 대해 다시 생각하게 된 지점이다.
Uncertainty를 숨기지 말아야 한다
SLAM/perception에서 uncertainty는 오래된 주제이다. 하지만 learning-based locomotion pipeline에서는 uncertainty가 종종 latent 안에 묻혀버린다. network가 알아서 처리해주기를 기대하는 식이다.
DreamWaQ++의 confidence filter나 adversarial observation noise는 이 문제를 조금 다른 방식으로 다룬다. sensor가 틀릴 수 있고, point cloud가 noisy할 수 있고, extrinsic calibration이 어긋날 수 있다는 것을 training 과정에 넣는다.
그런데 앞으로 SLAM이 control과 더 깊게 연결되려면 uncertainty를 더 명시적으로 넘겨주는 방향도 중요하다고 생각한다.
예를 들어 control policy에게 단순 height만 주는 것이 아니라, 다음과 같은 정보를 함께 줄 수 있다.
이 cell의 height는 10 cm로 추정된다.
하지만 최근 observation이 적어서 confidence는 낮다.
edge일 가능성이 높다.
surface normal은 불안정하다.
여기는 dynamic object 때문에 다시 확인해야 한다.
사람도 모르는 지형에서는 조심한다. 로봇도 마찬가지로 “여기를 안다”와 “여기를 모른다”를 구분할 수 있어야 한다. POMDP 관점에서 보면 이것은 belief의 sharpness 문제이다. 확신이 높은 belief와 불확실한 belief는 같은 action으로 이어지면 안 된다.
SLAM이 나아가야 할 방향
DreamWaQ++를 보고 나서 내가 생각하는 SLAM/perception의 방향은 다음과 같다.
1. Pose-centric SLAM에서 action-centric SLAM으로
전통적인 SLAM은 pose와 map이 중심이다. 하지만 robot이 실제로 행동하려면 pose accuracy만으로는 부족하다.
Legged robot에게는 다음 정보가 더 직접적이다.
- 다음 발이 닿을 곳의 geometry
- body가 지나갈 수 있는 clearance
- 발을 끌 가능성
- 미끄러질 가능성
- contact하면 버틸 수 있는 surface인지
즉 map의 품질을 pose RMSE만으로 평가하는 것은 부족하다. 앞으로는 action success와 연결된 perception metric이 더 중요해질 수 있다.
2. Global map보다 local predictive representation
모든 상황에서 global map이 필요하지는 않다. 특히 dynamic locomotion에서는 local prediction이 더 중요하다.
0.2초 뒤 front foot이 닿을 곳
0.5초 뒤 body가 통과할 공간
1초 뒤 gait를 바꿔야 하는 terrain
이런 short-horizon prediction이 locomotion에는 더 직접적이다. SLAM은 long-term consistency와 short-term actionability 사이의 trade-off를 더 명확히 봐야 한다.
3. Multi-rate sensor와 control loop를 함께 설계하기
SLAM에서는 sensor timestamp alignment도 중요하지만, control과 붙으면 더 빡세진다.
Depth, LiDAR, IMU, joint encoder, policy, PD controller가 모두 다른 rate로 돈다. perception output이 100 ms 늦으면, 이러한 latency로 인해 빠르게 움직이는 robot의 오작동을 야기할 수도 있다.
그래서 앞으로의 perception module은 단순히 “현재 map”을 주는 것이 아니라, latency-aware하고 prediction-aware해야 한다.
4. Active perception
DreamWaQ++ conclusion에서도 active tilting camera 이야기가 나온다. 나는 이 방향이 꽤 중요하다고 생각한다.
지금까지 SLAM은 주어진 sensor stream을 잘 처리하는 문제에 가까웠다. 하지만 legged robot에서는 sensor를 어디로 향하게 할지도 action의 일부가 될 수 있다.
계단을 올라갈 때는 발 앞을 보고, gap을 건널 때는 landing area를 보고, downhill에서는 아래쪽 surface를 더 확인하는 식이다.
즉 perception은 passive module이 아니라, control과 함께 움직이는 active module이 될 수 있다.
5. Learned policy가 쓰기 좋은 map
SLAM output이 사람이 보기 좋은 map일 필요는 없다. 물론 debugging과 human communication을 위해 human-readable map은 중요하다. 하지만 policy가 직접 쓸 representation은 다를 수 있다.
예를 들어 neural latent, local height feature, traversability embedding, uncertainty field가 classical point cloud보다 더 유용할 수 있다. 중요한 질문은 이것이다.
이 representation은 downstream policy가 더 좋은 action을 고르게 만드는가?
이 질문을 중심에 두면 SLAM의 설계 기준이 조금 달라진다.
다시 POMDP로 돌아오면
처음에는 POMDP가 control/RL 사람들이 쓰는 이론적인 말처럼 느껴졌다. 그런데 DreamWaQ++ 연구를 통해 mapping 관점에서 생각해보면 SLAM에서 쓰이는 개념과 크게 다르지 않다는 것을 느꼈다.
POMDP는 그냥 다음 사실을 말한다.
로봇은 세상을 다 보지 못한다.
그런데도 행동해야 한다.
그래서 history로 hidden state를 추정해야 한다.
이 문장은 SLAM과 거의 같은 정신을 가진다. SLAM도 sensor measurement만으로 보이지 않는 trajectory와 map을 추정한다. 다만 legged locomotion에서는 추정해야 할 hidden state가 더 넓다. pose와 map뿐 아니라 contact, friction, terrain affordance, sensor delay, actuator condition까지 포함된다.
그래서 나는 앞으로 SLAM이 단순히 “where am I, what does the world look like?”에서 멈추면 안 된다고 생각한다. 더 action-facing한 질문으로 가야 한다.
내가 지금 무엇을 할 수 있는가?
어디를 밟을 수 있는가?
무엇을 확신하고, 무엇을 모르는가?
다음 action을 위해 어떤 observation이 더 필요한가?
이 질문에 답하는 SLAM이 legged robot과 embodied AI에서 더 중요해질 것 같다.
정리
DreamWaQ++를 POMDP 관점에서 다시 보면, 논문의 여러 module들이 조금 더 자연스럽게 보인다.
- Actor는 partial observation만 보고 action을 낸다.
- Critic은 simulation에서 privileged state를 보고 학습을 도와준다.
- Proprioceptive encoder는 내부 상태와 hidden dynamics를 추정한다.
- Exteroceptive memory는 느리고 noisy한 외부 관측을 control loop에 맞게 정리한다.
- Multi-modal mixer는 proprioception과 exteroception을 policy가 쓸 context로 압축한다.
- 이 context latent는 POMDP에서 말하는 belief의 실용적인 근사처럼 볼 수 있다.
SLAM/perception 입장에서 얻은 교훈은 다음이다.
좋은 map이란 항상 가장 정확하고 큰 map이 아니라, robot이 다음 action을 잘 고르게 만드는 representation일 수 있다.
앞으로 SLAM이 legged locomotion이나 embodied AI와 더 깊게 연결되려면, pose accuracy와 global consistency만이 아니라 actionability, uncertainty, latency, active sensing까지 같이 봐야 한다.
결국 내가 요즘 느끼는 방향은 이렇다.
SLAM은 map을 만드는 기술에서, robot의 belief를 업데이트하고 action을 가능하게 하는 기술로 넓어져야 한다.
이렇게 생각하면 POMDP도, DreamWaQ++의 multi-modal memory도, SLAM이 가야 할 방향도 조금 같은 그림 안에 들어온다.